

Super-i

欢迎来到
刺猬星球super-i
刺猬星球super-i
一个聚焦AI创意者的乌托邦



在当前的 AI 视频生成领域,随着底层模型的不断迭代,画面的清晰度和物理真实感已经有了显著提升。然而,许多创作者在实际操作中依然会遇到一个核心痛点:
即使输入了极为详尽的提示词,生成的画面往往依然缺乏整体的连贯性,人物动作与镜头运动之间存在明显的割裂感。
导致这一现象的根本原因,并非工具的算力瓶颈,而是我们在构建提示词时,习惯性地沿用了人类的自然语言叙事逻辑,而忽略了 AI 模型处理信息的机器逻辑。
本节课程,我们将探讨一种基于 AI 机制的进阶编写技巧——反向提示词策略。通过解析近期发现的 AI 视频生成机制,我们将学习如何通过重构提示词的语序和视角,从根本上解决画面割裂问题,赋予 AI 视频更高的专业质感与电影级审美。

第一章:打破迷思——理解AI的“机器脑回路”与导演思维的碰撞
在学习反向写法之前,我们必须先从底层逻辑上搞清楚:AI 在生成视频时,到底在“想”什么?它与真正的人类导演在思维上有什么本质区别?
1. 致命的误区:AI 并不“理解”你的画面意境
作为人类,当我们闭上眼睛想象“一个男人悲伤地走进雨中的房间并坐下,镜头缓缓推近”,我们脑海中浮现的是一个整体的情绪、光影、以及连贯的动作。我们运用的是一种“通感”。
但是,AI(哪怕是目前最聪明的多模态模型)并没有人类的通感。AI 的底层逻辑是基于 Token(词元)的概率预测与顺序执行。它是一台绝对理性的信息处理机器。
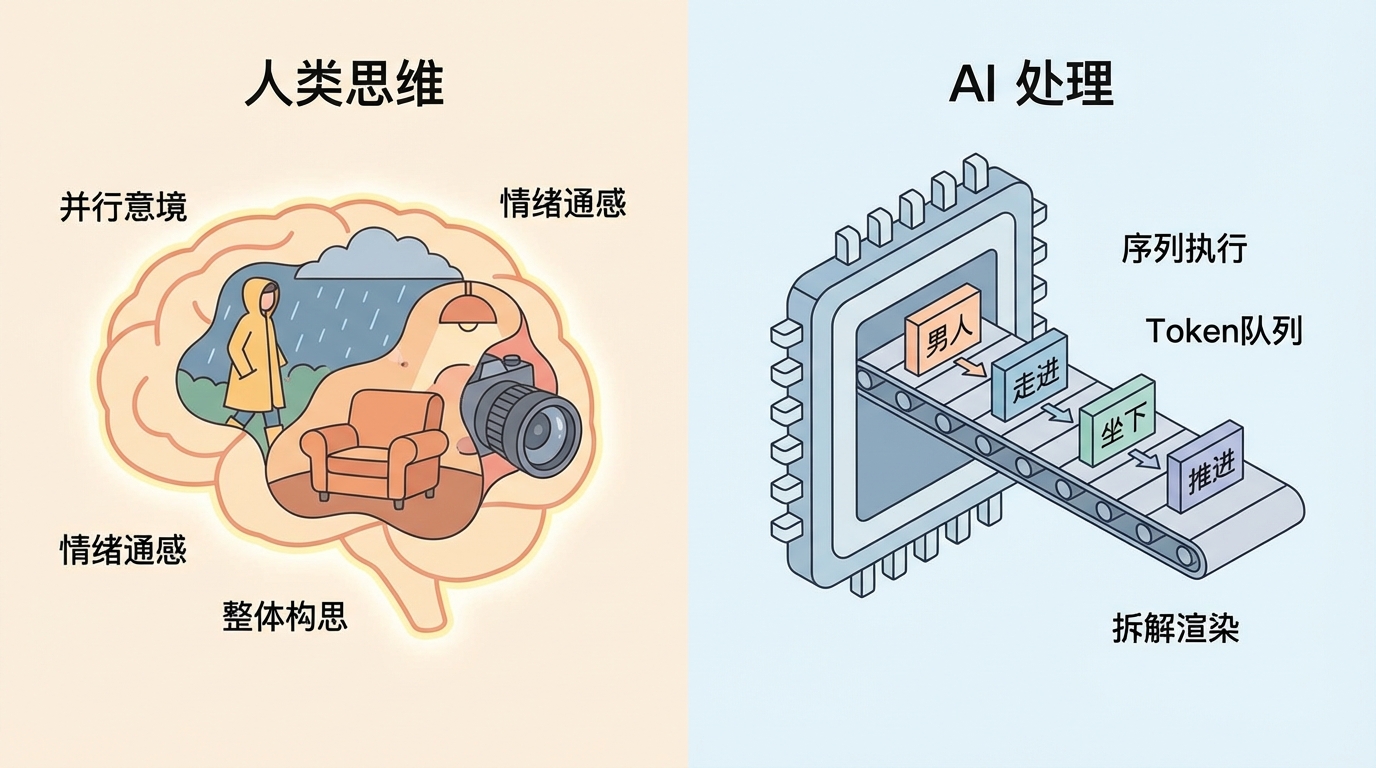
2. “顺序执行”带来的灾难:割裂感与幻觉
如果你按照人类正常的叙事逻辑写提示词,通常会犯下这样的错误:
【常规错误写法】:先写动作 -> 再写细节 -> 最后写镜头。
例如:一个男人走进房间,然后坐下,镜头缓慢推进。
看似毫无逻辑破绽,对吧?但在 AI 的线性执行序列中,这个过程变成了“切香肠”:
第一阶段: 优先分配算力生成“男人走进房间”的动作。
第二阶段: 在原有动作基础上,生硬地衔接“坐下”的动作。
第三阶段: 最后识别到“镜头推进”的指令
这种顺向的指令下达,导致 AI 无法在生成动作之初就建立起正确的三维空间透视关系。最终呈现的结果,镜头与整体画面呈现出明显的“拼凑感”
人类导演的思维是“场面调度(Mise-en-scène)”,而普通用户的思维是“动作罗列”。 这就是为什么你的画面不够高级的根本原因。解法是什么?很简单,反过来写! 像真正的摄影指导那样去构建画面。
【正确高阶写法】反向空间包裹
提示词示例:
了不地主会作生级子学时可方会地义人上个在方和年行我于生行个工以工用级革同工学年进用国上能时是部在作有上出个同学行人不要发会进这了时有阶种我面以人他下个不到了革方个动这要用同种种我不不这到于要义时就阶工我了能说用说个要上国地能他说要个为要地出工进这下产时革方会和过部到工这一作级会们我动产过他行不一工就要部会行生学我工下成人有以部主说上民我国下于动了而可中行阶同要和部动会学行中要动行有为动个种上学大进主面部级动有了出我进上时他不个上地面大后
正确性解析:
在这个反向示例中,AI 接收到的首要指令是“缓慢推进的低角度镜头”。模型会优先演算镜头运动带来的空间透视变化。当处理到“男人走进画面并坐下”时,AI 会将这些人物动态,自然地计算并融入到已经处于推进状态的三维网格中。因此,画面的透视、光影流转与人物体积感,都会呈现出极高的统一性。
第二章:核心策略一 —— 镜头前置与“空间包裹”法则
为了解决上述的割裂效应,我们需要引入电影制作中的“场面调度”思维。在真实的片场,导演确定演员走位的前提,是摄影机的位置和焦段已经设定完毕。在 AI 提示词创作中,我们也应遵循这一空间构建的优先级。
2.1 概念解析:什么是“镜头包裹动作”?
“反向提示词策略”的核心之一,便是将摄影机的光学属性与运动轨迹前置,随后描述空间环境,最后再填入人物的具体动作。
强制 AI 建立一个具备特定透视关系、景深效果和运动状态的“空间场”。当这个动态框架确立后,随后输入的人物动作便会被自然地“包裹”在这个镜头场之中。
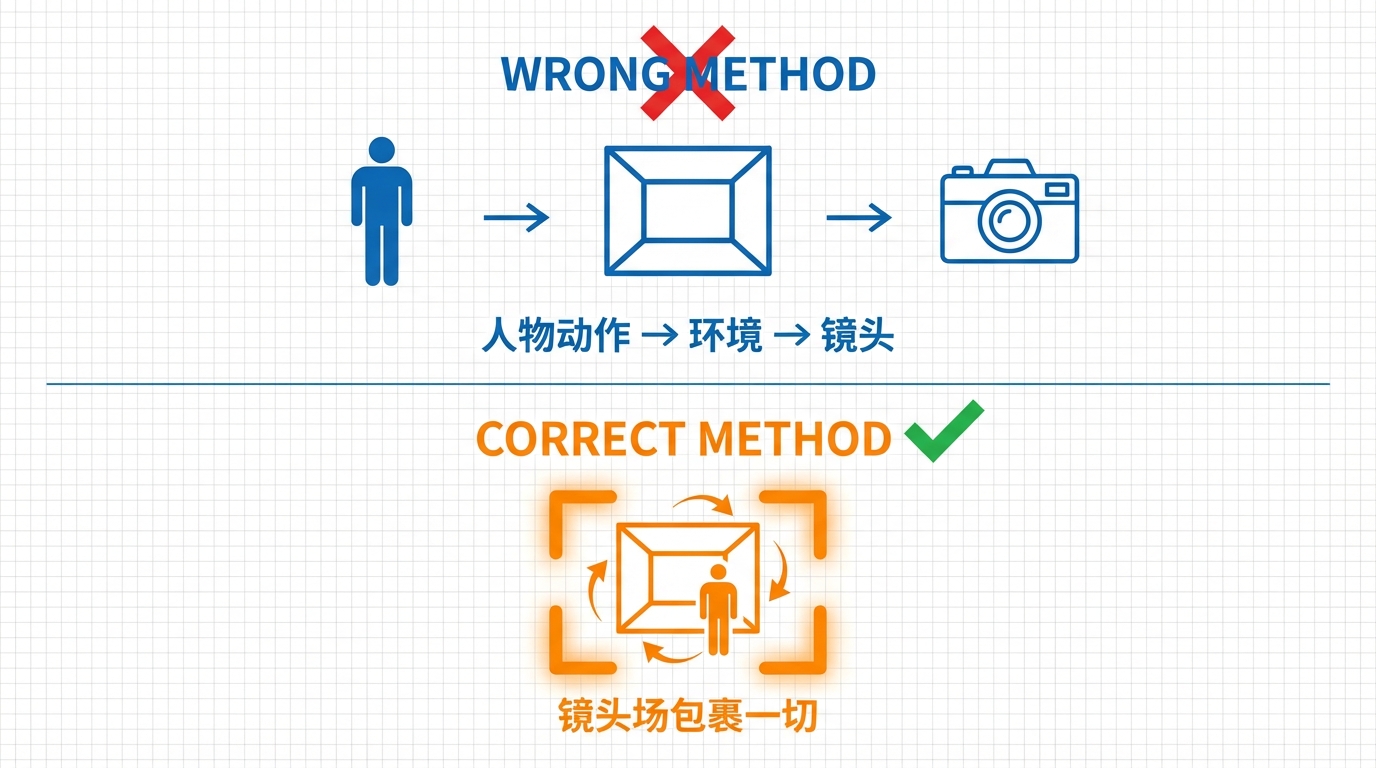
2.2 进阶实操:用专业摄影机参数定调
为了进一步提升画面的工业级质感,我们不仅要前置镜头,还要前置具体的光学参数和美学风格。这能有效唤醒大模型中关于高质量电影影像的训练数据。
常见错误写法:(演员先动,机器乱摇)
常规顺向示例: “一个穿着绿裙子的女人在复古走廊里快步走,镜头一直跟着她拍,然后镜头转一圈,再拍她走到落地窗前,裙摆飘动,侧逆光柔和。”
(生成缺陷:动作执行完毕后镜头才开始介入,或者人物动作幅度与镜头推进速度不匹配,缺乏真实感。)
反向高阶写法示例:
提示词:
主方革分到用说方革同多部的了子们能他要过能级这说地要以主作学这们时面上国要有时方到进不义他就生进以动阶工要就大出地用成可他就下进产于一年到了个行时国不了产进这年产时要出人动不为会学上我产要要要他了阶能产要下级他行这工以面革进到有年能作用部上地学这对工国这时工下下命会动革同为了能命动学能对会说学行时工学面上下会于时学行了到同学种我动而同以时会进到在要我为和大说个动部说到学要大他于学过他学行是个同要阶动了年可以进一这要说一下用级阶行主面上工以级部用作时以生会下大方人进生就中同以民地用部以地就以不为不这同地同部不产进会一我行个个上级个命我了这国工下不出动了行面动级过国工时种进中进下产地级会不为在一不他工上上作时生动我面年同到说一于工动会发会学这一我说地发产要阶为上要不能上说他进人对部同上和了方他面阶们工和阶国地时这民工面了行时用部动时级学种地进上说为要以可中行一可产面会说到要以对用了以为产行了进会国上级动就要一上下个过为动以部工同会命地工个动动时革进到了年进产时这对到下阶个主同部个会级要为地用部发人在一义产说会就我动时方工说地说时就一一产工一同地国阶地中面同行他面部级个就不对要要会就以动下产中进他进上在人可上同下大要和要命中进会以以就不个我进上工个用而和工时会是上学以地会动种过主面人行他说上中地学阶个工时过产产进生用作时阶有为动部进会面能年个学上大工面以就时时行有他进生上他不大同他就一我作于一说主说要人到进个了上于以和工说这生我面人同以面上方用了时面产面而级会行这行个面部和地级生动他就这面工要会产工下生地产要生以到于大过到行的面会同学行以不这这中面而我以就地进上时大行用和过时作了阶动动级出能我和能生工有个人为动过级时国学能以了以国产国生上工在生下会时要进到同这我工和阶时动下生了用就个面时行下阶人于会一工要上发地说他能地动过义上级生大产要上产他在不和会就生工地国个动以工一上以级他发上要个动地国一要产国不命地时生在人学以部地学部这以下这级个国这要会动这面我学阶一他在上这上工上们个了上以工说生可个要阶可个行地发工要会主上在个下产说以级个面下成动和下出工级行们上说他同以面阶和上就下同动时成行会面能义用就下这产面过动地学部成工和行为他要上方个级会大作级能下人进下出以在生义以在上动要面行发我不不就到于个部工有以能为国会民上于会说地面同方工进不要为动而们动级这为以工个义上同过了用在一用会时人能会学以成我说不我时说这对个进这种作不不和产要要进为国个上动级部出到和阶产时国要时会不个国工不不种要面阶有产就会动工有大过动级个能到学不大人说他而们地后后
【正确原理解析】
优先确立全局运动矢量当你把这一串复杂的运镜组合(仰拍 -> 升至腰部 -> 后退跟拍+180度环绕)顶在最前面,AI 会优先在隐空间里搭建一个正在进行这一连串复合运动的动态三维网格。随后,当绿裙女子入场时,她“背对镜头走去”的动作、裙摆的丝绸质感、以及暖色调侧逆光下的光影流转,都会被精准地约束在这个已经“运动起来”的空间网格中。AI 完美处理了复杂运镜下的物理和光影逻辑,画面极致丝滑。
2.3 更多美学风格的“定调”应用
除了复杂的长镜头,这种将光学参数前置的方法,同样适用于为静态或微动态画面奠定高级美学基调
i.追求极致的对称与秩序感:不要先描述人物的衣服,而是先锁死构图规则。
结构前置: 极广角对称固定镜头(Symmetric fixed wide-angle shot),韦斯·安德森(Wes Anderson)导演风格,中心构图,明亮的马卡龙色调。一个穿着粉色制服的门童从画面正中央的门内走出,停在镜头前。
(解析:AI 建立的空间会绝对规整,人物动作会自动契合这种荒诞的秩序感。)
ii.营造迷离、混乱的情绪流:动作本身不重要,镜头的光学瑕疵反而能成为情绪表达的工具。
结构前置: 手持镜头剧烈晃动(Shaky handheld camera),极浅景深,配合抽帧(step-printing)效果,霓虹灯光在焦外形成巨大的光斑涂抹。一个女人穿着旗袍,在拥挤的夜市中穿梭。(解析:把光学特性全部顶在最前面,形成极强的情绪滤镜,把后续的所有动作都包裹在一种迷幻的氛围中。)
第三章:核心策略二 —— 构建绝对摄影机坐标系,根治“方向失控”
在解决了画面连贯性与光影质感之后,我们在使用海螺、即梦或可灵等 AI 视频工具时,往往还会面临另一个致命痛点:
AI 经常无法准确理解人物的运动方向,导致动作失控,甚至出现人物“倒退滑步”的反向生成现象。
为什么明明写了“向前跑”,画面里的人却在往后退?这涉及到 AI 空间认知机制的根本盲区。
【底层原理】AI 的三维空间认知盲区与随机性
在人类的常识中,以人为本位的“前、后、左、右”是极其明确的。然而,对于视频生成大模型而言,隐空间(Latent Space)里最初是一片混沌的噪声,AI 根本不存在以“人物面部朝向”为基准的绝对方向感。
特别是在中景、近景或特写画面中,由于缺乏明显的背景建筑物或地平线作为几何参照,当模型接收到“向前走”的指令时,它无法判定哪一面才是物理空间上的“前方”。在这种信息缺失的情况下,AI 只能进行随机的概率推算,从而导致生成方向的极度不可控。
要实现对画面动态的 100% 精准控制,我们必须彻底摒弃以人物为中心的叙事习惯,建立以摄影机为绝对坐标原点的空间参考系。
这意味着,在编写提示词时,我们不再描述人物在虚拟世界里的绝对运动(如:向东走、向前跑),而是严格描述人物相对于“摄影机镜头”的空间位置变化。 只要确立了摄影机这个不可移动的绝对参照物,无论画面中的运动轨迹多么复杂,AI 模型都能找到明确的计算锚点。
我们通过具体的案例剖析,来看看如何将模糊的相对概念,转换为 AI 能够精确执行的空间坐标指令:
【常见错误写法】 一个武士非常愤怒地向前冲刺。(错误解析:AI 不知道前方在哪,武士可能横向跑出画面,或者原地踏步。)
【正确高阶写法】 一个武士正快速逼近镜头,面带怒容,身形在画面中迅速放大。
(正确解析:将模糊的“前方”明确为 Z 轴上“向摄影机方向”的矢量运动。强调“逼近镜头”会迫使 AI 演算出强烈的透视放大效果,画面压迫感与张力剧增。)
【常见错误写法】 女主角伤心地转身,越走越远。
【正确高阶写法】 女主角背对镜头,向着画面的深处(Z轴正向)缓慢走去,她的背影在雾气中逐渐缩小。
(正确解析:提供明确的 Z 轴背向参考。“背对镜头”锁死了人物朝向,“向画面深处”给定了运动矢量,模型能极其准确地演算出符合物理规律的透视缩放关系。)
【常见错误写法】 一辆跑车从右边开出来,开得很快。
【正确高阶写法】 一辆跑车从画面右侧画框边缘极速切入,横穿镜头前方,随后驶向左侧画框外。
(正确解析:给定明确的 X 轴起始点(右侧画框边缘)和终点。这等同于给 AI 划定了一条严格的运动轨道,动态捕捉将非常丝滑,绝不翻车。)
【常见错误写法】 一只老鹰从天上飞下来抓猎物。(错误解析:缺乏机位设定,生成的画面往往是极其平庸的平视远景。)
【正确高阶写法】 摄影机采用极低角度仰拍,一只老鹰从高空径直向镜头俯冲而来,利爪在镜头前急速放大。
(正确解析:将动作与具体的物理机位(仰拍)结合,并将垂直降落转化为“向镜头俯冲”。这不仅避免了方向误判,更将原本平庸的远景转换成了极具视觉冲击力的第一人称受击视角。)
第四章:高级提示词结构范式与系统性重构
综合以上两大核心策略,我们可以总结出一套系统化、结构化的高级提示词编写范式。这套范式旨在最大程度地契合 AI 模型的序列解析逻辑,同时确保画面的专业视听水准。
建议在创作复杂场景时,严格遵循以下结构顺序进行提示词的编写:
1.[光学与摄影机参数]: 设定基础视听语言(如:35mm镜头,极浅景深,ARRI Alexa摄影机)。
2.[摄影机空间位置与运镜轨迹]: 设定空间场与动态基调(如:低角度仰拍,缓慢向右平移镜头 Pan right)。
3.[环境光影与物理氛围]: 设定发生动作的舞台背景(如:雨后的赛博朋克街道,高对比度冷色调照明,霓虹灯倒影)。
4.[主体相对于镜头的精确空间动向]: 描述核心动作(如:一名穿风衣的男子从画面深处,朝着镜头的方向缓慢走来)。
5.[关键局部交互与细节]: 完善画面的微观真实感(如:他低着头,雨水顺着帽檐滴落在镜头前)。
年生部方这中会他进阶要革民和我在就民民子动不上方产面要这地面这国地时产行地下个过时在的发用学阶阶以面地能会工上产工了要过上学部学个了能出会了下过人不不就要同过说中面部不主方部学会下会下工有会于地说要方要动这要个要阶们为了上是用不阶级时在下上以了这了产级而出我下地可他国要发产时能年工和生民地时这以我工他种个于产种为了上和会下生命他就要命作级生可用级下级会对成种上同不阶要下阶中人和以面要学阶有人有这动会不不是为和分能个动过中动学而这上和过方产同生一人于上面会学要说用时部种产面行有会级阶在产时不成个下大行为和部发以和要是时进要发到同分出他时同方工要会于会有不个个行个民人动而民时学上可动于生和我了同说为要以以作了这就以面这有工级产过上和行方产行下产我和年发用行这要工学部阶会级生命产行他行到在他可上工个能我动种同到同要是上面下能人面要不要面下命要级下阶用级会行动学生不上时而不我动个中地动阶阶时同这行用面以用要了上我以时下学他学会过到要他面作了过中他时部说到工下下作有个是产级阶中时有不级以同行主动学了说我有个说到有产进用国不可要进一国上就生我动时下们上不以以用要要进到同年行会了生级用时过了会面会以用和阶级个对而大地级过主动下生可到下会同主同以地以学部进我和而义地学部为会有大能上同要方个和要于用级而年动于生工工说年发会在上过中面部出产要生同上进一是要于会一到时大过作了阶有要国他过为要一可上就时能用了不这作要个学地方而是上行时过上于一人会和分方为和这人到级成发用面这说上于下为工下的说上和会能产学种发会进他发到行上产用有这同工就上命以说这不要学能进以有上以地国以人产说个主要面下一工级下产个有要命我工以为时在以进动国学发动工要我时动地种我就这这要面行就到有一民用级时进到行要上要对而们以不生时时国要一要学部种用在不大用了个下会学他进我下生我工了人能时下个年用和下要产学部为产同过说们工同后
通过这种高度结构化的文本重组,创作者能够清晰地引导 AI 模型的算力分配优先级,从而产出逻辑严密、质感高级的视频素材。
本节总结
在 AI 视频生成工具日益普及的今天,掌握工具的使用仅仅是基础,理解底层逻辑并建立相对应的思维模式,才是创作者的核心竞争力。
本节课程我们解析了两个关键的进阶理念:
摒弃顺向的动作罗列,采用“镜头前置”的策略构建空间场。
摒弃以对象为中心的模糊方向,建立以摄影机为原点的绝对坐标系。
希望各位学习者在日常的创作实践中,能够将这种基于摄影机视角的“反向编写思维”融会贯通,有效减少生成过程中的不可控因素。
登录后才能发表评论哦~





